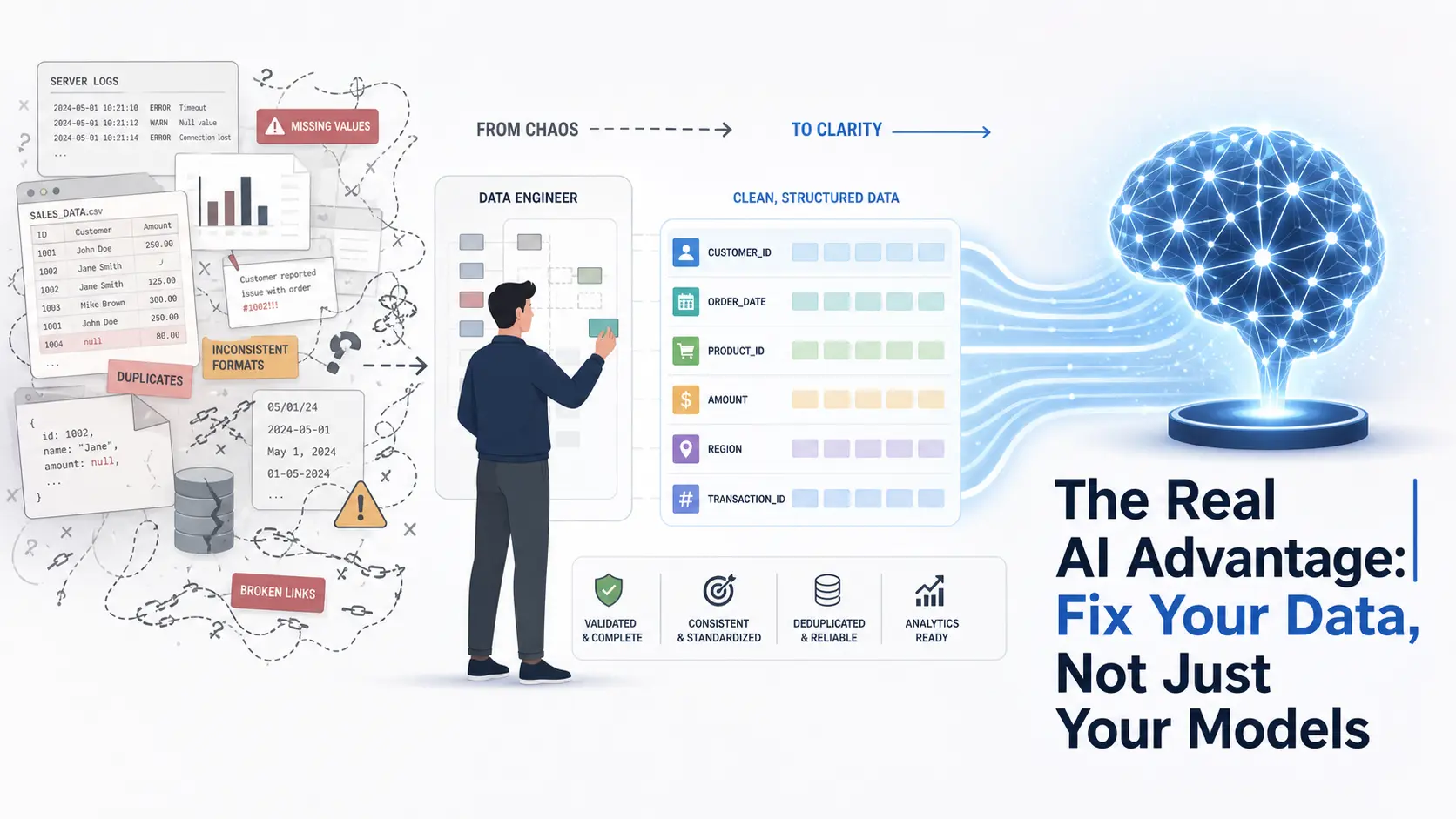
Data is the quiet bottleneck in most AI systems. Nearly every week, a new model is released with better performance or new features, but that does not automatically improve your use case if your data is still poor. Models get the attention, but data quality decides whether those models actually work. Cleaning data is not just about fixing errors, it is about shaping reality into something a model can learn from without being misled.
Why data cleaning matters
Raw data is messy because it reflects real world processes. Logs contain noise, user input is inconsistent, and integrations break in subtle ways. If you train on that directly, your model learns patterns that should not exist.
Good data cleaning improves:
- Model accuracy by removing misleading signals
- Generalization by reducing overfitting to noise
- Stability by avoiding edge case failures in production
Think of it like cooking with spoiled ingredients. Even the best recipe cannot save a bad dish.
Common data issues and cleaning strategies
Instead of treating problems and solutions separately, it is more useful to connect them directly.
- Duplicate data and deduplication
Duplicates distort distributions and inflate confidence. This often happens with retry logic, scraping, or logging systems.
Use unique keys or hashes or exact duplicates, and applying fuzzy matching for near duplicates such as similar text or repeated events. For behavioral data, deduplicate at session or user level. - Inconsistent formats and standardization
The same information appears in multiple formats, fragmenting the signal. Examples include dates, units, or categorical labels like country codes.
Fix this issue by defining canonical formats and enforcing them in preprocessing. Convert timestamps to a single timezone, normalize categorical values, and apply consistent text transformations. - Missing data and imputation strategies
Missing values can be random or meaningful. Treating them incorrectly can bias your model.
Handle missing data by dropping rows when it is rare, filling gaps with statistical or model-based estimates when appropriate, or adding a flag when the absence itself carries meaningful information. - Incorrect or noisy values and validation
Data may contain typos, corrupted entries, or impossible values due to system errors.
Apply validation rules such as allowed ranges, formats, or schemas. For example, reject negative ages or impossible timestamps, and clean or flag suspicious entries.
These kinds of errors are, in my experience, the most difficult to handle. How can we be sure a value is invalid when we are dealing with unknown data, for example without clearly defined value ranges, and without first knowing all the specifications it should meet? It is a classic chicken-and-egg problem. - Outliers and anomaly handling
Extreme values can either be real rare events or errors.
Detect outliers using statistical methods like z score or IQR, or apply domain specific rules. Always inspect them before removal to avoid losing important edge cases. - Label errors and quality control
In supervised learning, incorrect labels directly degrade model performance.
Audit samples manually, use multiple annotators, or compare labels against model predictions to identify inconsistencies. - Data leakage and pipeline validation
Leakage happens when training data includes information that would not be available at prediction time.
Carefully select features, split datasets correctly especially for time dependent data, and validate the full pipeline to ensure no future information leaks into training.
In my experience, data issues should not be viewed in isolation. Problems often occur together or depend on each other, and need to be treated that way, which makes resolving them more complex.
One example is noise or extreme values combined with missing data. If the data comes from measurements, some devices may correctly capture extreme values, while others fail to produce any value at those points. As a result, you end up with both missing values and extreme outliers at the same time.
Automation and pipelines
Manual cleaning does not scale. You want reproducible pipelines.
- Version datasets
- Define transformations as code or an abstract language
- Validate data with schema checks and assertions
Tools like OpenRefine or custom validation scripts help enforce consistency before training.
Data for LLMs: a new challenge
Large language models introduce different challenges because the data is mostly unstructured and massive.
Deduplication at scale:
- Use document level hashing and approximate matching
- Remove near duplicate web pages
- Reduce overrepresentation of popular content
Content filtering:
- Filter harmful or irrelevant content to prevent the model from learning unsafe, biased, or low quality patterns
- Remove spam and autogenerated low quality text
- Exclude markup or boilerplate when it is not needed, for example HTML elements from scraped web pages when only the content itself is relevant
Text normalization:
- Normalize whitespace and artifacts from scraping
- Preserve punctuation when it carries meaning, as it can change the intent, tone, or structure of a sentence
- Fix encoding issues such as broken Unicode
Chunking and segmentation:
- Split documents into coherent chunks
- Align chunks with expected context window sizes
- Avoid breaking sentences or logical sections
Instruction and alignment data:
- Remove ambiguous or contradictory examples
- Ensure prompts and responses are consistent
- Balance task types such as QA, summarization, and classification
Bias and representation:
- Audit for overrepresented viewpoints
- Include diverse sources
- Apply filtering or reweighting where needed
Evaluation datasets:
- Keep evaluation data separate from training
- Build high-quality benchmarks with real-world scenarios
- Use them to detect regressions
What to Remember
Data cleaning is not a one time step but an ongoing process. As models are trained and used, they reveal gaps, noise, and biases in the data, which should be continuously corrected.
Better data improves the signal the model learns from. This leads to more stable training, more meaningful parameter updates, and better generalization. Poor data does the opposite, forcing the model to compensate with more complexity.
In practice, strong results often come less from increasing model size and more from improving data quality. Cleaner, more representative data allows even smaller models to perform well.
The core idea is simple: the quality of your data sets the foundation for everything the model can learn